Edit : there's a new component in the new JDeveloper version. You can view it in action
here.
-------------------------
I
some time ago posted one OTN JDeveloper Forum about
how to export the content of a dvt:pivotTable to Excel. Unfortunatly, no reel response appears, even with the help of
Frank Nimphius. Concerning this problem, at today's date, the situation is :
- Using af:exportCollectionListener adf component does not work for dvt:pivotTable component ;
- This feature is in the roadmap for the next release of JDev ;
- To export ADF pivot table, you don't have a choice : using a 3rd party java library (did you say GOFJ ?)
So I searched, looked around, and finally figured the situation out. And this is a blog. So let's be story telling-y. Here's what I do :
1. Looking for a way to access the content of the current pivot table displayed in UIOf course : before investigating in java api for Excel, or how to prompt an "open file" in web browser, this first point had to be figured out since it's the the most critical one. If accessing content of pivot table is not possible, the use case will not be solved.
The component pivot table was bound to the backing bean. My first try was to use methods from oracle.adf.view.faces.bi.component.pivotTable.UIPivotTable : I did not find anything to browse the content of the pivot table.
At this point I posted on the forum and got no answer. Then I abandonned this and put some colors in the pivot table, with the help of
this post from AMIS blog. I adapted the class to my needs (colors and style). It's basicly something like this :
public class PivotManager {
public CellFormat getDataFormat(DataCellContext cxt) throws SQLException {
CellFormat cellFormat = new CellFormat(null, null, null);
Object currentData = cxt.getValue();
// My own color and style rules
// ....
return cellFormat;
}
public CellFormat getHeaderFormat(HeaderCellContext cxt) {
CellFormat cellFormat = new CellFormat(null, null, null);
Object currentHeader = cxt.getValue();
// My own color and style rules
// ...
return cellFormat;
}
But then ! Eureka. The whole content plus the headers are accessed in this class. Let me explain.
2. Figuring the way data cells are accessedWhen naviguation comes to the page wich encapsulate the dvt:pivotTable component, two things happen in the lifecycle of the application :
- The backing bean scope of the page begin
- One request scope is launched (the bean for colors and styles, PivotManager, is of request scope) each 10 columns.
Yes, you read it right. Each cell calls the PivotManager.getDataFormat for the tenth first columns (neverming the number of lines); then, a new request is launched in the lifecycle. To be clearer :
If you put a new attribute and add this in the getDataFormat method :
public class PivotManager {
private int count=1;
public CellFormat getDataFormat(DataCellContext cxt) throws SQLException {
CellFormat cellFormat = new CellFormat(null, null, null);
Object currentData = cxt.getValue();
if (currentDate != null) {
System.out.println("Current Cell Data Accessed in PivotManager class : "+ cxt.getValue() + " ; " + this.count);
this.count++;
// ....
You'll see that no matter how many lines you got, the order in wich the method will be called is :
- The first cell to be called when the page is load for the first time is the one on the upper top left corner ;
- Then it'll go on the same line (so the first), one cell by one cell, to the cell of the tenth column
- Then the first cell of the second line
- To the cell on line two and column ten
- ...
- The the final line and tenth column : then a new instance of PivotManager is created ; scope-wise, it's a new request, since PivotManager is a bean of request scope.
To help you understand, one (crapy) diagram of what's happening for a pivotTable with 11 to 20 columns.
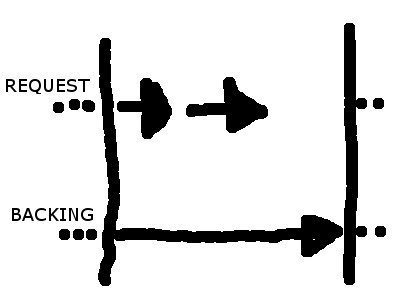
I tried to tweak the view object tuning properties, and the iterator in the page definition : it's still ten column * total number of lines at a time (so a "request-time). If someone knows, please share : I'm interessted. That's not really problematic : it's just the Excel export has to be handled in another bean of a different scope, since the backing bean is way too big (there's a lot of stuff on that page).
3. Java Excel API use / Web browser prompt "open or save as"So I create a bean of scope application (let's be Rambo like ; no I'm kidding. Neither backing, request, pageFlow or session scope were right) named PivotToExcel, wich will handle all exports features. So first, I'll share the PivotManager modified, with new getDataFormat method. You will note that getHeaderFormat does not contain an exportToExcel method. This is because you can get dimensions name of the data currently accessed in PivotManager with cxt.getQDR().getDimMember("xxDimNamexx"). So
one cell data is owned by the total number of dimensions.
public class PivotManager {
public CellFormat getDataFormat(DataCellContext cxt) throws SQLException {
CellFormat cellFormat = new CellFormat(null, null, null);
// My own color and style rules
// ....
// Block to get the PivotToExcel bean
FacesContext fc = FacesContext.getCurrentInstance();
ValueExpression ve = fc.getApplication().getExpressionFactory().createValueExpression(fc.getELContext(), "#{PivotToExcel}", PivotToExcel.class);
PivotToExcel pivotToExcel = (PivotToExcel)ve.getValue(fc.getELContext());
// Block to format data ; in my case, there's three dimensions : CodeProjet, Agence // and Trigramme. This first part is for handling null values.
String dimCP = "";
String dimAgence = "";
String dimTrigramme = "";
if (cxt.getQDR().getDimMember("Agence") != null) dimAgence = cxt.getQDR().getDimMember("Agence").toString();
if (cxt.getQDR().getDimMember("CodeProjet") != null) dimCP = cxt.getQDR().getDimMember("CodeProjet").toString();
if (cxt.getQDR().getDimMember("Trigram") != null) dimTrigramme = cxt.getQDR().getDimMember("Trigram").toString();
// The data cells contains numbers in te float format
float valeur = 0;
if (cxt.getValue() != null) valeur = Float.parseFloat(cxt.getValue().toString());
// Calling the method of PivotToExcel bean to add the current cell to the Excel sheet
pivotToExcel.addCell(valeur, dimCP, dimTrigramme, dimAgence);
return cellFormat;
}
public CellFormat getHeaderFormat(HeaderCellContext cxt) {
CellFormat cellFormat = new CellFormat(null, null, null);
// My own color and style rules
// ...
return cellFormat;
}
For creating an Excel file, I'm using
JExcel API. It's pretty practical : you can create writable workbook as file or outputStream, create or add worksheet, format cells (numbers, date, boolean ; colors and style). You may find one
tutorial, a
FAQ and the
java docs.
PivotToExcel of application scope is instanciated once : the first time the bean is getted in getDataFormat method of PivotManager. It creates one writableWork when initiated. Workbook.createWorkbook(new File(fileName +".xls")); creates a new Excel sheet in the current directory, which you can get via getCurrentDir() method of this bean. Cells are added with addCell(...) methd : here you'll have to write your own code : mine was to specific. Using the JExcel tutorial, you'll see that it's easy. Cells are added ...
voila !
To open the Excel file, just create an action component with actionListener bound to a backing bean that gets the current instance of PivotToExcel (you can use the code of PivotManager, to get PivotToExcel) : then just call exportToExcel(). What will happen :
- The workbook will be written in the current directory with the specified name. To access the current directory, the method getCurrentDir() at the end of the class is here for that !
- The workbook is closed.
- public static synchronized void downloadFile(String filename, String fileLocation, String mimeType, FacesContext facesContext) is called : it basicly copy the Excel file created into the outputStream of ((HttpServletResponse)facesContext.getExternalContext().getResponse()).getOutputStream()
- facesContext.responseComplete() : "signal the JavaServer Faces implementation that the HTTP response for this request has already been generated (such as an HTTP redirect), and that the request processing lifecycle should be terminated as soon as the current phase is completed" Javadoc.
public class PivotToExcel implements Serializable {
private WritableWorkbook workbook;
private WritableSheet sheet;
private String fileName;
private String pathToFile=this.getCurrentDir()+"\\";
public PivotToExcel() {
create();
}
public void create() {
// Generating a name
java.text.SimpleDateFormat sdf = new java.text.SimpleDateFormat("yyyy.MM.dd.HH.mm.ss");
this.fileName = sdf.format(new Date());
try {
workbook = Workbook.createWorkbook(new File(fileName +".xls"));
} catch (IOException e) {
}
sheet = workbook.createSheet("First Sheet", 0);
}
public void exportToExcel () {
// you could call a method to put lay your sheet out
// ...
// Writing the workbook and the temporary file
try {
workbook.write();
} catch (IOException e) {
}
catch (java.lang.ArrayIndexOutOfBoundsException aioobe) {
}
try {
workbook.close();
} catch (IOException e) {
} catch (WriteException e) {
}
// Method to prompt in the web browser the download window
downloadFile(fileName +".xls",
this.pathToFile,
"application/vnd.ms-excel",
FacesContext.getCurrentInstance());
// You delete the temporary file
File f = new File(pathToFile + fileName +".xls");
f.delete();
// And create a new one
this.create();
}
public void addCell(float arg1, String dim1, String dim2, String dim3) {
// Your own way to insert in the sheet
// For help see JExcel tutorial
}
public static synchronized void downloadFile(String filename, String fileLocation, String mimeType,
FacesContext facesContext) {
ExternalContext context = facesContext.getExternalContext();
//String path = context.getInitParameter("externalFiles") + fileLocation;
String path = fileLocation;
String fullFileName = path + filename;
File file = new File(fullFileName);
HttpServletResponse response = (HttpServletResponse) context.getResponse();
response.setHeader("Content-Disposition", "attachment;filename=\"" + filename + "\"");
response.setContentLength((int) file.length());
response.setContentType(mimeType);
try {
FileInputStream in = new FileInputStream(file);
OutputStream out = response.getOutputStream();
// Copy the contents of the file to the output stream
byte[] buf = new byte[1024];
int count;
while ((count = in.read(buf)) >= 0) {
out.write(buf, 0, count);
}
in.close();
out.flush();
out.close();
// cut lifecycle
facesContext.responseComplete();
} catch (IOException ex) {
System.out.println("Error in downloadFile: " + ex.getMessage());
ex.printStackTrace();
}
}
public String getCurrentDir () {
return System.getProperty("user.dir");
}
3. Result 4. The end
4. The endAnother solution could have been to use the iterator and construct my own pivot table directly in the Excel sheet. But the way it's done here ensure that the pivot table in the Excel sheet will be the same as the one in your web browser.
 So, the af:selectManySchuttle is the adf components that implements this.
So, the af:selectManySchuttle is the adf components that implements this. See ? Easy ! An inconvenient is that we cannot create an entity layer. But you’ll see by the end of this paper that it’ll be of no use. Let’s go on with the model layer : with this I’ve created three view objects and one view link. This last one is just to be able to choose on whom people we’re going to assign knowledge.
See ? Easy ! An inconvenient is that we cannot create an entity layer. But you’ll see by the end of this paper that it’ll be of no use. Let’s go on with the model layer : with this I’ve created three view objects and one view link. This last one is just to be able to choose on whom people we’re going to assign knowledge.
 Values attributes of both af:selectManySchuttle and f:selectItem are important here.
Values attributes of both af:selectManySchuttle and f:selectItem are important here.






